Source: The Conversation – UK – By Matthew Mokhefi-Ashton, Lecturer in Politics and International Relations, Nottingham Trent University
This month marks the 50th anniversary of a much-revered classic of American cinema, All The President’s Men.
The 1976 movie starring Robert Redford and Dustin Hoffman was an adaptation of Bob Woodward and Carl Bernstein’s 1974 book of investigative journalism detailing their two-year unravelling of the Watergate conspiracy. The shocking scandal brought down a president and profoundly shook Americans’ trust in government.
On June 17 1972, operatives working for President Richard Nixon’s Committee for the Re-election of the President (often satirically referred to as CREEP) were caught breaking into the Democrat party’s national headquarters at the Watergate complex in Washington. The subsequent attempted cover-up eventually led to the resignation of Nixon and many in his administration going to jail.
The book and film led to several words and phrases entering the popular lexicon, including “deep throat” as shorthand for informants, the expression “follow the money” and of course the use of the word “gate” tacked on at the end of a word to denote a scandal. The film is probably the most famous movie about journalism ever made and helped shape the public’s view of who journalists were and how they functioned.
In many ways it’s strange to see an America where the media were so trusted. At the time a significant majority of Americans held the view that if the Washington Post or New York Times printed something, then it must be true. This is in contrast to today where trust in the US media is at an all-time low.
Woodward and Bernstein’s success was partly helped by the fact that the news cycle was a lot slower. Newspapers only went to print once or twice a day, so journalists had valuable time to check sources, look at records and discuss what they were doing with colleagues and editors.
Crucially, if they weren’t sure of the merits of a story, it was easier to shelve it for the next day. The current 24-hour news cycle makes this much more difficult. Journalists are under constant pressure to publish as soon as possible, leaving far less time for verification and reflection. Speed is rewarded over accuracy and the competitive scramble to be first can mean stories go out before they are fully formed.
The funding model is also fundamentally different. Many local newspapers were owned by families who lived in the cities where they were based and had been there for generations (in the case of the Washington Post with Katherine Graham). They often had a personal stake in the community.
There were still press barons, for instance William Randolph Hearst. The Orson Welles film Citizen Kane was based on his life story. But even at their most powerful, these proprietors operated within a media ecosystem where credibility was the currency that kept readers buying.
The media was funded by sales and advertising, giving journalists the freedom to work on a story. Today, by contrast, there is a focus on chasing clicks with articles either made up of lists or with clickbait headlines designed to be shared across social media.
How the press shaped the national agenda
The early 1970s was a world where the press were just as important – if not more so – than TV in shaping the national agenda. While commentators and columnists such as Walter Winchell had always been celebrities, the film established the idea of journalists as household names in their own right.
This has arguably been problematic in some ways as it could be claimed that it encouraged a more ego-driven approach to reporting, where the journalist-as-hero narrative risks making the story about the person covering it rather than the subject itself.
It was also an environment where the media still focused on the idea of reporting the news rather than making it. Today many media platforms explicitly market themselves as investigative journalism and see their role as setting the agenda. More traditional outlets see this as the media becoming too activist and ideological. There are proponents on both sides of the debate; All The President’s Men seems to take the view that the media report the news and the public decide how to interpret it.
However, the film’s very existence complicates that position. Woodward and Bernstein did not merely report events – they led the debate. The question of whether the press should be a mirror held up to power or a force that actively shapes political outcomes is still ongoing.
It’s worth noting that 1976 also saw the release of Network. This movie was entirely fictional and told the story of a broadcaster, played by Peter Finch, who has a mental breakdown live on air. He becomes “the mad prophet of the airwaves”, telling his audience to shout out of the window: “I’m mad as hell and I’m not going to take it any more!”
While All The President’s Men served as a monument to what the press had achieved and what it could and should be, Network, though billed as outrageous satire at the time, has proven a significantly more accurate prediction of the future.
In the film the TV network is owned by a vast corporation with financial interests in several other areas. While Woodward and Bernstein are professionals doing their job, they do it largely without animosity. Their goal is to uncover the truth of the Watergate conspiracy, not to bring down the president. Network predicted a world where profit is everything and media and politics are fundamentally adversarial, with reporters aiming to make their audience as angry as possible.
Fifty years on, the question is not which film got it right (all the evidence suggests Network). It is whether the world All The President’s Men celebrated was already vanishing, even as audiences and critics were praising it.
Matthew Mokhefi-Ashton does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation – in French – By Oumaima Omari Harake, Doctorante et Enseignante en Sciences de Gestion -Spécialité Outils de Gestion et Sant Publique-, Université de Poitiers
L’intelligence artificielle se développe au Maroc dans plusieurs établissements hospitaliers, comme outils d’aide au diagnostic, en télémédecine pour la prise en charge de populations rurales, etc. Les premiers résultats sont prometteurs. Mais ces technologies posent aussi nombre de questions d’ordre éthique, juridique et aussi de fiabilité. Par exemple, le fait que la plupart des systèmes d’IA en santé soient développés sur des données issues de populations occidentales pose question.
Le Maroc a franchi un cap symbolique en 2024 avec le lancement de sa stratégie nationale de développement de l’intelligence artificielle et la feuille de route « Maroc IA 2030 » qui a placé la santé parmi ses secteurs prioritaires.
Mais comment cette révolution technologique peut-elle s’adapter aux réalités du système de santé marocain, entre espoirs légitimes et défis considérables ?
Des applications concrètes qui transforment déjà la pratique médicale
L’intelligence artificielle commence à s’implanter dans plusieurs hôpitaux marocains, particulièrement dans les centres hospitaliers universitaires de Casablanca et Rabat. Les algorithmes d’aide au diagnostic médical montrent des résultats prometteurs, notamment en radiologie où ils détectent avec une précision comparable aux radiologues expérimentés certaines anomalies pulmonaires ou osseuses.
Prenons l’exemple concret d’une radiographie thoracique : là où un radiologue peut mettre plusieurs minutes à analyser l’image et rédiger son compte-rendu, un algorithme d’IA peut identifier en quelques secondes les zones suspectes, signalant par exemple une pneumonie ou une tumeur potentielle. Le médecin garde bien sûr le dernier mot, mais dispose d’une aide précieuse, particulièrement dans les services surchargés.
La télémédecine constitue un autre domaine d’application majeur. Dans un pays où les disparités géographiques d’accès aux soins restent importantes, les systèmes d’IA permettent de faire le lien entre patients des zones rurales et spécialistes urbains.
Imaginons une patiente diabétique vivant dans une région reculée de l’Atlas : grâce à une application mobile équipée d’IA, elle peut photographier ses analyses de sang, recevoir une première analyse automatisée et être mise en relation avec un endocrinologue si nécessaire, sans avoir à parcourir des centaines de kilomètres.
La gestion hospitalière bénéficie également de ces technologies. Les algorithmes prédictifs aident à anticiper les besoins en ressources, à optimiser la planification des blocs opératoires et à gérer les stocks de médicaments. Un système d’IA peut par exemple prédire les pics d’affluence aux urgences en fonction de multiples facteurs (épidémies saisonnières, accidents, conditions météorologiques) et permettre d’ajuster les effectifs en conséquence.
Des défis éthiques et juridiques à ne pas sous-estimer
L’enthousiasme technologique ne doit pas occulter des questions fondamentales. La protection des données de santé constitue le premier enjeu. Le Maroc dispose certes d’une loi sur la protection des données personnelles, mais son cadre juridique reste encore incomplet concernant spécifiquement les données de santé et leur utilisation par des algorithmes d’IA.
Concrètement, que se passe-t-il lorsqu’un hôpital collecte les dossiers médicaux de milliers de patients pour entraîner un algorithme ? Qui a accès à ces données ? Comment garantir leur anonymisation ? Peuvent-elles être transférées à l’étranger pour être traitées par des entreprises technologiques internationales ? Ces questions restent largement sans réponse.
L’équité d’accès représente un autre défi majeur. Si l’IA est déployée prioritairement dans les grands centres urbains, elle risque d’accentuer les inégalités territoriales existantes. Un cardiologue de Casablanca pourrait bénéficier d’un électrocardiogramme analysé instantanément par IA, tandis qu’un médecin généraliste isolé dans une commune rurale continuerait à travailler avec des moyens limités.
La question de la responsabilité médicale soulève également des interrogations inédites. Imaginons qu’un algorithme rate un diagnostic de cancer sur une mammographie et que la patiente ne soit diagnostiquée que des mois plus tard, à un stade avancé. Qui est responsable : le radiologue qui a validé l’analyse automatisée, l’établissement qui a adopté le système, ou la société qui l’a développé ? Le cadre juridique marocain actuel n’apporte pas de réponses claires.
Les biais algorithmiques, un risque invisible mais réel
Un problème plus subtil mais tout aussi crucial concerne les biais des algorithmes. La plupart des systèmes d’IA en santé sont développés sur des données issues de populations occidentales. Leur transposition directe au contexte marocain pose question : les particularités génétiques, épidémiologiques et socioculturelles de la population marocaine sont-elles suffisamment représentées ?
Un exemple parlant : un algorithme de diagnostic dermatologique entraîné principalement sur des peaux claires pourrait avoir des difficultés à détecter correctement un mélanome sur une peau plus foncée. De même, un outil d’évaluation du risque cardiovasculaire calibré sur des populations européennes pourrait sous-estimer ou surestimer les risques pour des patients marocains ayant un profil génétique et des habitudes alimentaires différents.
Pour que l’intégration de l’IA dans le système de santé marocain soit réellement bénéfique, plusieurs conditions doivent être réunies. D’abord, développer un cadre réglementaire spécifique combinant protection des données, certification des algorithmes médicaux et définition des responsabilités. L’Union européenne a récemment adopté une législation sur l’IA (l’AI Act) dont le Maroc pourrait s’inspirer.
Ensuite, investir massivement dans la formation des professionnels de santé. L’IA ne remplacera pas les médecins mais transformera leurs pratiques. Un jeune médecin marocain doit aujourd’hui apprendre non seulement la sémiologie clinique traditionnelle, mais aussi à interpréter les recommandations d’un algorithme, à identifier ses limites et à conserver son esprit critique.
La recherche locale en IA santé doit également être encouragée. Les universités marocaines doivent développer des algorithmes entraînés sur des données locales, reflétant les spécificités de la population et des pathologies prévalentes au Maroc.
Enfin, une approche inclusive s’impose. Le déploiement de l’IA en santé doit s’accompagner d’investissements dans les infrastructures de base : connectivité Internet dans les zones rurales, équipements médicaux numériques, formation du personnel… L’objectif étant que la technologie serve à réduire les inégalités plutôt qu’à les creuser.
L’intelligence artificielle offre au Maroc une opportunité historique de moderniser son système de santé et d’améliorer l’accès aux soins de millions de citoyens. Mais cette transformation ne réussira que si elle s’accompagne d’une réflexion éthique approfondie, d’un cadre juridique adapté et d’une volonté politique de garantir l’équité.
La technologie n’est qu’un outil : c’est la manière dont nous choisissons de l’utiliser qui déterminera si elle servira réellement l’intérêt général.
Oumaima Omari Harake ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
Source: The Conversation – in French – By Julien Pomarède, Associate professor in International Politics, Promoter of the WEAPONS Project (FNRS – 2025-2028) (Université de Liège) – Research Fellow REPI ULB. Promoter « WEAPONS » Research Project (FNRS – 2025-2028), Université de Liège
La guerre moderne est marquée par une dérive où la violence est avant tout un fait procédural et auto-suffisant, détaché de ses finalités politiques ou de fondements éthiques. Depuis la Première Guerre mondiale jusqu’aux conflits actuels, cette logique se traduit par un fétichisme technologique de la destruction, où l’efficacité militaire est mesurée par l’intensité des frappes. Aujourd’hui, malgré des technologies plus « précises », cette dynamique persiste et s’accompagne d’un affaiblissement des normes morales et juridiques, produisant des guerres longues, dévastatrices et souvent stratégiquement inefficaces.
Chacun à sa manière, Hannah Arendt (1906-1975), Günther Anders (1902-1992) et Zygmunt Bauman (1925-2017) ont identifié un danger essentiel propre à la modernité : l’aliénation de la raison humaine par la raison technique. De l’Holocauste aux armes nucléaires, ils ont pointé du doigt ce même danger dans le domaine de la violence organisée : une mise en technique de la violence telle que son exécution ne suivrait plus que le culte de sa propre procéduralité, aux dépens du jugement humain et éthique.
Ce regard permet de cerner une pathologie qui structure et rend possible la conduite dite « stratégique » des guerres actuelles et modernes.
Pathologie de la pensée stratégique
La guerre menée contre l’Iran suscite une critique récurrente : l’incapacité de l’administration Trump comme du gouvernement Nétanyahou à définir un objectif politique au-delà de la démonstration de force.
Des objectifs sont publiquement articulés, certes : en bref, il s’agit d’empêcher l’Iran d’acquérir des capacités nucléaires. Mais, d’une part, ils sont vagues et fort incertains. Plus fondamentalement, l’horizon de la guerre semble ne pas sortir d’une accumulation de destructions massives, illustrée par le discours militariste du secrétaire à la guerre, Pete Hegseth, qui érige la puissance de feu en vertu quasi sacrée, et, en dépit de la fragile trêve actuelle, par la menace du président de renvoyer l’Iran à « l’âge de pierre », l’extension des cibles vers les infrastructures civiles ayant d’ailleurs déjà débuté.
Toutefois, limiter cette dérive à quelques dirigeants serait une erreur. Les administrations Trump et Nétanyahou ont certes poussé cette exaltation de la force particulièrement loin, mais elle s’inscrit dans une histoire plus profonde : celle d’un fétichisme technique et pathologique de la violence qui structure la pensée stratégique moderne, cette manière instrumentale-rationnelle par laquelle les États conçoivent l’usage organisé de la force pour le transformer en résultats politiques. Car, même si ces présentes guerres et leurs motivations peuvent paraître dépourvues de logique sensée, elles n’auraient pas été rendues possibles sans l’existence d’une raison stratégique d’arrière-fond qui rationalise cette violence, en lui donnant sens et légitimité. Sans quoi, par exemple, les militaires ne seraient pas invités à donner des conférences de presse pour commenter les opérations aux côtés des responsables politiques.
À gros traits, ce fétichisme technique se manifeste à travers deux aspects.
D’une part, l’usage des armes répond moins à des stratégies cohérentes d’articulation des moyens et des fins de la guerre qu’à une logique d’optimisation technique ou d’empilement des destructions. Les élites politico-militaires donnent, certes, des objectifs à la guerre — heureusement, dirait-on. Mais ces buts sont largement soumis à une violence qui a pour logique sa propre exécution procédurale et où les succès se résument, par conséquent, à comptabiliser le nombre d’ennemis tués et d’infrastructures détruites. Le niveau de destruction, et de respect du droit international humanitaire, varie, de même que les décisions politiques et militaires peuvent être plus ou moins (dé)mesurées dans ce qu’elles cherchent à détruire ; mais la trame technocentrée demeure.
D’autre part, cette croyance attribue aux armes une capacité quasi magique à résoudre les conflits, ou du moins à en assurer une sortie, produisant un obsurantisme technique de la guerre. Ce phénomène nourrit des guerres prolongées où la vision et l’escalade de violence supplantent la perspective politique et stratégique.
Ce culte technocentré, c’est donc fondamentalement un culte de la férocité qui, sous des airs froids, rationnels et sophistiqués, érige la capacité et le volume de destruction en valeur intrinsèque. En bref, taper plus fort et plus vite que celui d’en face. Et cette férocité technocentrée produit des résultats souvent limités ou des échecs, à des coûts humains et matériels variables mais souvent considérables, et dont les conséquences peuvent s’étaler des années après le conflit.
Ce que l’on voit en Iran, en Ukraine ou à Gaza est la continuité d’une pathologie de la pensée stratégique qui s’avère donc moins stratégique que technocratique dans sa manière d’envisager la guerre. Il convient de penser ce phénomène sur le temps long, dans un moment où les digues éthiques et morales d’encadrement de cette férocité cèdent à grande vitesse.
Le fétichisme technique de la férocité au XXᵉ siècle…
La Première Guerre mondiale constitue une sorte de moment charnière où le gigantisme de la destruction devient une fin en soi. Deux conditions rendent possible cette évolution. D’un côté, l’industrialisation accélérée de la production d’armements depuis la fin du XIXe siècle ; de l’autre, la guerre de positions, qui encourage une escalade technologique destinée à débloquer le front, tout en renforçant paradoxalement son immobilisation.
Ainsi, les tranchées se transforment en laboratoire d’innovations dont l’objectif premier est de tuer, mutiler ou asphyxier les corps à des échelles encore jamais vécues. L’artillerie se diversifie : nouveaux calibres, nouvelles munitions, obus à fragmentation pensés pour maximiser les mutilations des corps, gaz destinés à brûler les chaires et étouffer les poumons. Et cette logique fut poussée loin. L’armée française procéda ainsi à des prélèvements de viscères de soldats intoxiqués pour mesurer les effets des agents chimiques et en optimiser la toxicité. À cette croissance technologique macabre s’ajoutent des débats minutieux sur les rendements létaux des tirs, les commandements militaires donnant instruction à leurs troupes de privilégier les zones de tir confinées pour améliorer l’absorption des gaz et accroître leur létalité.
On présente souvent la Seconde Guerre mondiale comme le retour de la mobilité et de la « vraie » stratégie, par contraste avec celle de 14-18. Mais la logique technocentrée reste intacte. L’ultima ratio de la guerre demeure la destruction de masse et son affinement technique, ce que Michael Sherry qualifia de « fanatisme technologique ». Les bombardements stratégiques, dont les recherches ont montré les résultats limités l’illustrent de manière éclatante. Les incendies de Hambourg (1943), Dresde (février 1945) et surtout Tokyo (1945) reposent sur une quête explicite d’annihilation par le feu.
L’armée américaine va jusqu’à reconstruire sur son site de test dans le désert de l’Utah (Dugway) des îlots urbains japonais et allemands afin d’étudier l’adhérence du gel napalm (substance incendiaire) et la vitesse de propagation des flammes parmi ces différentes structures d’habitation, l’objectif étant de déterminer scientifiquement quels types de bombes seraient les plus efficaces pour incinérer les villes. Une des conclusions qui ressortit de ces tests est que les villes japonaises étaient plus facilement inflammables, le bois et le papier étant largement utilisés dans les habitations. L’apocalypse incendiaire de Tokyo en fut le résultat. Les bombardements atomiques des 6 et 9 août 1945 parachevèrent ce fanatisme technologique.
Les conflits de la guerre froide prolongent ce culte technocentré de la férocité. Dès 1950, la guerre de Corée ouvre la voie. Les États-Unis recourent à un bombardement incendiaire débridé pour contenir la poussée sino-coréenne, utilisant encore plus de napalm que contre le Japon durant la Seconde Guerre mondiale. Des villes nord-coréennes sont quasi entièrement rasées. Des officiers reconnaissent qu’il n’y avait même plus de cibles militairement valables bien avant la fin du conflit, tellement que les bombardements furent intenses, ce qui n’empêcha pas l’US Air Force de continuer à bombarder. Le récit documenté que fait Robert Neer de ces atrocités dans Napalm soulève le cœur. Et ce n’est même pas une victoire qui résulta de cet acharnement.
En Indochine, l’armée française s’appuie sur l’artillerie, le napalm (d’abord obtenu via un appui américain) et les bombardements pour compenser l’impasse face au Viet Minh. Dans l’artillerie, les rapports soulignent systématiquement que la référence reste « la brutalité » de la Grande Guerre. Villages, rizières, stocks de nourriture et bétail sont pilonnés, bombardés et incendiés, dans l’espoir illusoire que le surplus de destruction puisse compenser.
Après Diên Biên Phu, les États-Unis prennent le relais au Vietnam et poussent cette fuite en avant jusqu’à l’absurde, qui tourne là aussi au massacre de masse. Comme l’a minutieusement documenté Nick Turse, le Vietnam fut une litanie d’atrocités appuyée par une croyance inaltérable en la validité stratégique de déploiements de moyens de destruction à peine imaginables et leur analyse statistique.
… et au XXIᵉ siècle
Après la guerre froide, les armées occidentales entrent dans une ère de retenue plus grande dans l’usage de la force, avec un accent mis sur le respect du droit international humanitaire. Les conflits des années 1990-2000 ne présentent plus les traits des destructions massives du XXe siècle. Pour autant, le technocentrisme de la violence persiste, rhabillé par le langage de la précision et le développement de nouvelles technologies (guidage laser, bombes « intelligentes », algorithmisation du ciblage). Même si le niveau physique de dégâts est effectivement moindre, les résultats n’en seront pas meilleurs.
La « guerre contre la terreur » des années 2000-2010 en est l’illustration. En Afghanistan comme en Irak, l’impasse donne lieu à la même réponse : augmenter les moyens d’une guerre high tech. Entre 2009 et 2012, le « surge » en Afghanistan multiplie les opérations, le niveau de violence augmente, de même que les pertes civiles. Des épisodes particulièrement brutaux demeurent, comme des villages rasés à coups d’obus d’artillerie. Pourtant, l’équation politico-stratégique ne se modifie pas. Malgré les dépenses militaires très élevées, ces contre-insurrections débouchèrent sur des guerres civiles et constituèrent des échecs cuisants.
Le recours aux assassinats ciblés à l’échelle globale via les drones, censé réduire la guerre à une série d’opérations ponctuelles, produit une conflictualité à durée indéterminée. Comme s’attelle à le documenter le Cost of War Project, la « guerre contre la terreur » a eu des conséquences néfastes et très larges, allant des pertes humaines aux atteintes aux libertés individuelles, en passant par le déplacement des populations jusqu’à l’érosion du droit international (conception extensive de la légitime défense, tortures, détentions extra-judiciaires) qui s’accélère aujourd’hui.
En Libye, pour éviter de s’enliser comme en Irak ou en Afghanistan, l’Otan choisit en 2011 une campagne aérienne de quelques mois, légalement présentée comme limitée à la protection des civils réprimés par Kadhafi, conformément au mandat du Conseil de sécurité (résolution 1973). Officiellement, il ne s’agit pas d’une opération visant le changement de régime, même si, là aussi, la question se pose de l’outrepassement du mandat de l’ONU par l’Otan vers un changement de régime de facto. Cette stratégie de service minimum fut à nouveau louée sur la base d’un technocentrisme, celui de la supériorité de la guerre aérienne, les officiers de l’Otan défilant en conférence de presse pour dénombrer, images à l’appui, les dégâts causés par les bombardements aux capacités militaires du régime de Tripoli.
Ce culte technocentré irrigue les conflits actuels. La différence, et non des moindres, étant un affaissement généralisé du respect du droit international et le retour à une férocité qui, un temps contenue, au moins dans les armées de l’Otan, semble retrouver ses affres du XXe siècle. En Ukraine, les deux camps se sont enfoncés dans une guerre d’artillerie et de drones où la mesure du conflit se résume au nombre de missiles tirés, de soldats tués, de drones abattus et d’infrastructures détruites. Du côté russe, l’acharnement dans la férocité inclut le bombardement et le pilonnage des civils.
En réponse aux effroyables attaques du Hamas du 7 octobre 2023, l’extrême intensité des bombardements israéliens à Gaza et l’usage croissant de systèmes d’IA, qui déshumanise encore plus la violence en automatisant la sélection de cibles et en accélérant les frappes, montrent que l’optimisation technologique de la férocité prime sur toute considération humaine ou politique. La fin, c’est la désolation, l’anéantissement généralisé de la vie, aussi bien la destruction physique des populations palestiniennes que des conditions mêmes de la vie à Gaza.
Dans la guerre en Iran, la trajectoire de la violence reste encore à définir. Il faut voir où mènera la fragile trêve actuelle. Mais, au fond, la férocité compense l’impasse et l’absence de vision. L’extension progressive de l’éventail des cibles vers les infrastructures civiles, l’obsession des instances politico-militaires américaines à rendre compte des « progrès » de la guerre à travers le dénombrement quantitatif des destructions, la récente décision du blocus du détroit d’Ormuz, sont la continuité d’une dynamique où la force n’apparaît pas comme autre chose que comme une dynamique qui se nourrit de sa propre logique.
Obscurantisme technique
De la Grande Guerre à l’Iran, en passant par l’Ukraine et Gaza, le fétichisme technique de la violence charrie une conviction institutionnalisée selon laquelle l’acharnement dans la férocité, le fait de frapper plus fort, plus vite, et avec plus de moyens, peut finir par payer. Et ce culte persiste, malgré ses échecs répétés, comme si l’accumulation des désastres ne suffisait jamais à l’invalider. Tout cela sans même parler des conséquences environnementales catastrophiques de cet obscurantisme technique de la guerre, qu’il contribue par ailleurs à invisibiliser.
Ce constat invite à une révision en profondeur de cet obscurantisme technique à partir duquel la force militaire est pensée. Et il y a urgence, dans un monde qui se remilitarise, où la puissance militaire est célébrée comme garante de stabilité (y compris par les Européens) et où les barrières morales tombent à grande vitesse, laissant présager un avenir où la dévastation du vivant ne fera que s’étendre.
Julien Pomarède a reçu des financements de l’ULiiège et de la Fondation nationale pour la recherche scientifique (FNRS) (projet WEAPONS – 2025-2029).
L’ultimatum lancé par Donald Trump à l’Iran, suivi d’un recul rapide, a donné lieu à de multiples moqueries. En effet, ce n’est pas la première fois, loin de là, que le président des États-Unis émet des menaces avant de se rétracter au dernier moment. Cette pratique peut relever d’un calcul de négociation fondé sur l’intimidation, mais elle peut aussi être lue comme le signe d’une incohérence devenue consubstantielle au trumpisme. À terme, la répétition de tels épisodes fragilise la crédibilité politique en affaiblissant la portée des déclarations présidentielles.
Mardi 7 avril 2026, le monde entier avait les yeux rivés sur Donald Trump. Dans une séquence de tension maximale, le président des États-Unis avait lancé un ultimatum au gouvernement iranien, affirmant être prêt à « détruire une civilisation entière » si ses exigences n’étaient pas satisfaites. Cette déclaration, d’une violence extrême, s’inscrivait dans une logique d’escalade verbale caractéristique de ses prises de parole en contexte de crise. Pourtant, une heure avant la fin de son ultimatum, il annonçait qu’il allait examiner les dix conditions posées par l’Iran et entérinait un cessez-le-feu de quinze jours.
Si cette désescalade ne peut qu’être saluée au regard des risques encourus, elle a immédiatement suscité une lecture critique désormais synthétisée par un acronyme, TACO, pour « Trump Always Chickens Out », que l’on peut traduire en français par « Trump se dégonfle toujours ».
Une pratique récurrente
Ce concept de « TACO » ne relève pas seulement de la formule médiatique. Il tend à conceptualiser une dynamique récurrente dans la pratique politique de Donald Trump : une initiale montée aux extrêmes, suivie d’un recul stratégique.
L’expression « se dégonfler » renvoie ici à l’idée d’un abandon de la menace initiale, non pas nécessairement par faiblesse, mais dans le cadre d’une séquence de négociation où l’excès verbal constitue un levier. Cette logique s’apparente à une stratégie de maximalisation rhétorique : poser des exigences intenables ou proférer des menaces disproportionnées afin de créer un rapport de force, puis accepter un compromis qui apparaît, par contraste, comme une concession mesurée.
Toutefois, réduire cette pratique à une simple tactique de négociation serait insuffisant. La répétition de ce schéma dans le temps suggère qu’il s’agit d’un habitus politique, au sens d’une disposition durable à agir et à parler selon des modalités constantes. Depuis ses premières campagnes jusqu’à ses prises de position les plus récentes, Trump a systématiquement privilégié une rhétorique de l’excès : insultes, menaces, annonces spectaculaires. Mais cette radicalité discursive ne se traduit pas toujours en actes. Donald Trump a récemment réactivé l’idée d’un contrôle stratégique du Groenland, en insistant sur son importance militaire et énergétique face à la Russie et à la Chine. Il a durci le ton en évoquant la nécessité pour les États-Unis de sécuriser l’île, laissant planer une logique de contrainte plutôt que de simple négociation. Toutefois, aucune initiative diplomatique ou militaire concrète n’a été engagée après ces déclarations.
Le non-passage à l’acte devient, dès lors, un élément structurant de son mode de gouvernement.
Ce décalage entre parole et action appelle plusieurs interprétations. Il peut d’abord être compris comme une rationalité stratégique fondée sur une logique d’intimidation maximale. En énonçant des menaces extrêmes, Trump cherche à remodeler les anticipations de son adversaire en l’obligeant à intégrer un scénario de destruction totale. Cette projection du pire agit comme un levier psychologique puissant. Elle modifie le cadre de la négociation en rendant toute concession ultérieure acceptable, voire rationnelle, du point de vue de l’adversaire. Dans cette optique, la menace n’est pas destinée à être exécutée, mais à produire un effet en amont de l’action. Le recul final ne constitue donc pas un renoncement, mais l’aboutissement d’un processus où la parole remplace l’acte.
Cependant, une telle lecture, que l’on qualifiera de stratégique, se heurte à une seconde interprétation, plus critique, qui met en évidence les limites structurelles de cette pratique. Le décalage répété entre parole et action peut révéler une incapacité à assumer les conséquences concrètes des déclarations initiales. La radicalité du discours engage le président dans une logique dont il ne maîtrise pas nécessairement les implications, notamment face aux contraintes militaires, diplomatiques et institutionnelles. Le passage de la posture à la décision constitue alors un moment de tension, où les coûts potentiels de l’action apparaissent de manière plus tangible. Ce moment produit un réajustement, perçu extérieurement comme un recul, mais qui traduit en réalité une difficulté à transformer la parole en action.
Une crédibilité affaiblie
Ce phénomène met également en lumière une dissociation croissante entre communication et décision. La parole présidentielle tend à fonctionner de manière autonome, comme un instrument de mise en scène du pouvoir, indépendamment de sa traduction opérationnelle. Cette autonomie produit une inflation verbale caractérisée par la répétition de menaces extrêmes, sans articulation systématique avec une stratégie d’action cohérente. L’espace public se trouve ainsi saturé par des annonces spectaculaires qui ne débouchent pas sur les mesures correspondantes.
Dans les deux cas, qu’il s’agisse d’une stratégie maîtrisée ou d’une contrainte subie, le résultat observable demeure identique. La parole politique perd progressivement sa capacité à produire des effets. À force de ne pas être suivie d’actes, elle s’expose à un phénomène d’usure qui affaiblit sa crédibilité. Les adversaires peuvent intégrer ce décalage dans leurs anticipations et ajuster leur comportement en conséquence, réduisant l’efficacité même de la menace. Le discours, initialement conçu comme un instrument de puissance, tend alors à se retourner contre son émetteur en contribuant à fragiliser sa position dans le jeu stratégique international.
Cette dynamique pose inévitablement la question de la crédibilité du discours politique. Qui peut encore croire à des annonces systématiquement démenties par les faits ? La crédibilité, en politique internationale comme en politique intérieure, repose en grande partie sur la prévisibilité et la cohérence entre parole et action. Or, la répétition du schéma « menace puis retrait » affaiblit la portée des déclarations présidentielles. À force d’annoncer des ruptures majeures sans les concrétiser, le discours perd sa capacité à produire des effets.
Cette problématique peut être éclairée par la notion de performativité. Un discours performatif est un énoncé qui produit l’action qu’il énonce : dire, c’est faire. Dans le cas de Trump, le discours se veut explicitement performatif : annoncer une sanction, une attaque ou une rupture doit en principe suffire à modifier le comportement de l’adversaire. Cependant, en l’absence de mise en œuvre effective, ce discours devient paradoxalement anti-performatif. L’écart entre l’énoncé et l’action annule l’effet attendu et peut même produire l’effet inverse : décrédibiliser la parole présidentielle.
Calcul élaboré ou incohérence ?
Enfin, il convient de s’interroger sur la nature de cette stratégie de communication. Est-elle pleinement intentionnelle ou résulte-t-elle des contradictions internes du président américain ? D’un côté, on peut y voir une méthode maîtrisée, fondée sur la théâtralisation du conflit et la recherche d’un avantage maximal dans la négociation. De l’autre, cette oscillation permanente entre radicalité et retrait peut traduire une difficulté à stabiliser une ligne politique cohérente, notamment sous la pression des contraintes institutionnelles, diplomatiques et militaires.
À l’approche des élections de mi-mandat de novembre 2026, la question de la stratégie TACO se pose avec acuité. Faut-il y voir une méthode délibérée ou le symptôme de contradictions internes ? D’un côté, cette stratégie peut être interprétée comme un outil de gestion de crise fondé sur une montée aux extrêmes, destinée à maximiser les concessions adverses avant un compromis. Elle permettrait d’éviter une escalade militaire tout en donnant l’image d’une fermeté initiale. De l’autre, elle peut traduire une difficulté à maintenir une ligne politique cohérente sous l’effet de contraintes institutionnelles et diplomatiques. Ces deux dimensions contribuent à produire une dynamique instable. À court terme, cette approche peut apparaître efficace en évitant des conflits ouverts. À moyen terme, elle risque d’affaiblir la crédibilité des États-Unis sur la scène internationale.
Dans ce contexte, la séquence iranienne d’avril 2026 pourrait constituer un test politique majeur, révélant si cette stratégie renforce ou fragilise durablement le leadership présidentiel.
Frédérique Sandretto ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
À quoi servent exactement les engrais phosphatés ? Peut-on s’en passer à l’heure où ces intrants agricoles apparaissent comme une source de pollution au cadmium ? Des recherches montrent que, depuis le siècle dernier, l’agriculture française a largement bénéficié de ces engrais issus d’importations. À moyen terme, en France, les stocks de phosphore accumulés dans les sols permettraient donc de s’en passer pour quelques décennies sans chute majeure de rendements. À long terme, cela nécessiterait, cependant, des changements importants de notre système agricole et alimentaire.
Alors que la pollution au cadmium (métal aux propriétés proche du zinc, ndlr), en partie issue de l’utilisation d’engrais minéraux phosphatés, est en passe de devenir un grave problème de santé publique, une question commence à s’imposer : pourrait-on se passer d’engrais phosphatés sans nuire aux rendements de l’agriculture ?
À court terme, il semblerait que l’on puisse se passer des engrais minéraux phosphatés en France, sans impact majeur sur la production agricole. La comparaison des stocks en phosphore des sols avec la demande en phosphore des cultures suggère que les stocks actuels pourraient répondre à la demande pendant soixante ans. Cette estimation témoigne de la forte disponibilité en phosphore des sols agricoles français. Au-delà de cette période, se passer de ces intrants nécessiterait des changements majeurs dans le système agri-alimentaire pour maintenir le même niveau de production agricole.
Mais pour comprendre tout cela, il faut commencer par revenir aux bases et se demander à quoi sert au juste le phosphore.
Un élément essentiel à la croissance de tous les êtres vivants
Le phosphore est un élément essentiel à la croissance de tout être vivant, car il intervient dans la constitution des molécules d’ADN, les transferts d’énergie entre cellules (ATP) et la structure des membranes et des os. Les cellules, les plantes et le vivant tout entier ont donc besoin de phosphore et, sans phosphore, il n’y a pas de vie telle que nous la connaissons. Une graine ne pourra ainsi jamais devenir une plante sans cet élément. Elle pourra tout juste commencer à germer en utilisant la réserve de phosphore qu’elle possède, et cela s’arrêtera là.
Fort heureusement, les sols sont naturellement pourvus en phosphore. Le phosphore est présent dans la roche et, lorsque celle-ci s’altère, du phosphore devient disponible dans le sol. Selon les types de sol, la disponibilité en phosphore est plus ou moins élevée, mais l’Europe est particulièrement bien lotie sur ce plan. Certaines régions d’Afrique ou d’Amérique du Sud, à l’inverse, ont des sols très vieux, car ils n’ont pas subi de glaciation récente, qui se sont donc appauvris au cours de leur histoire.
Au-delà de la quantité totale de phosphore, la manière dont celui-ci est « fixé » aux différents constituants du sol définit également sa disponibilité pour les plantes.
Comment fonctionnait l’agriculture avant l’apparition d’engrais phosphatés ?
En France, avant l’utilisation des engrais minéraux phosphatés, les cultures poussaient donc en bénéficiant du phosphore naturellement disponible dans les sols agricoles, mais également de celui qui provenait des excréments animaux, comme le fumier ou le lisier.
Il y avait des transferts de phosphore d’une parcelle à l’autre. Lorsqu’une prairie était fauchée, le phosphore, présent dans sa biomasse et issu du sol sur lequel elle avait poussé, était donné en alimentation à des animaux présents à l’étable. Le phosphore ingéré à travers l’herbe par les animaux se retrouve en grande partie dans leurs effluents. Ces effluents peuvent ensuite être utilisés pour fertiliser une culture, comme le blé, à destination de l’alimentation humaine.
Ce mécanisme permettait de transférer du phosphore d’une parcelle en prairie vers une parcelle en grande culture. Ce mécanisme existe toujours aujourd’hui, mais il est moins marqué du fait de la séparation spatiale des cultures et des élevages.
Avant les engrais minéraux, on récupérait aussi le guano (amas de fientes d’oiseaux de mer riches en phosphore), présent sur certaines îles, pour fertiliser les sols agricoles. L’utilisation d’excrétions humaines pouvait également représenter potentiellement un autre apport de phosphore.
Les changements générés par l’arrivée des engrais chimiques
Avec l’arrivée des engrais chimiques, au début du XXᵉ siècle et leur utilisation massive après la Seconde Guerre mondiale, les rendements augmentent considérablement. Entre 1961 et aujourd’hui, le rendement du blé a, par exemple, triplé. Le fait d’avoir des systèmes agricoles plus productifs va ainsi augmenter nos besoins en phosphore.
D’autre part, les réformes de la politique agricole commune (PAC) de l’après-guerre entraînent une forte spécialisation agricole des territoires, c’est-à-dire une séparation dans l’espace entre les zones d’élevage et celles de grandes cultures, qui étaient jusque-là intimement liées.
Aujourd’hui en France, la Beauce est spécialisée dans les céréales et importe des engrais minéraux phosphatés pour répondre aux besoins de ses cultures. À l’inverse la Bretagne est une région spécialisée dans l’élevage (porcs, poulets, vaches laitières). Sur ce territoire les entrées de phosphore se font surtout par l’importation massive d’aliments pour les animaux qui contiennent du phosphore. Ce phosphore se retrouve en grande quantité dans leurs effluents, puis sur les sols à proximité et cause de sérieux problèmes environnementaux, comme les marées d’algues vertes liées à un phénomène d’eutrophisation des eaux.
Pourrait-on aujourd’hui se passer d’engrais phosphatés sans impacter les rendements ?
L’apparition des engrais phosphatés a ainsi bouleversé l’agriculture, en augmentant la production agricole et la disponibilité en phosphore des sols français par accumulation au cours du temps. Après un pic dans les années 1970, leur utilisation a nettement diminué. Ils sont aujourd’hui trois à quatre fois moins utilisés qu’il y a cinquante ans. Pourrait-on pour autant s’en passer totalement ?
C’est ce que nous avons cherché à savoir à travers des simulations évaluant l’évolution d’une agriculture mondiale biologique à 100 % pour ces cent prochaines années.
En France, nos sols sont naturellement pourvus en phosphore et se sont considérablement enrichis ces dernières décennies en raison de l’utilisation massive d’engrais minéraux phosphatés apportés dans des proportions bien supérieures aux prélèvements par les plantes. On estime que 60 % du phosphore que l’on trouve actuellement dans les sols français provient de l’utilisation passée et présente de ces engrais.
Cet héritage en phosphore des sols offre une opportunité de réduire drastiquement notre utilisation de ces intrants sans que cela affecte, en tous cas sur le court terme, la production agricole française.
L’« effet “starter” »
Si l’on regarde uniquement la différence entre la demande en phosphore des plantes, tout le long de leur cycle, et la quantité de phosphore disponible dans les sols agricoles, nos simulations montrent de fait qu’il n’y a pas d’effet à court terme sur les rendements si l’on arrête d’utiliser en France des engrais phosphatés.
Toutefois, nos simulations ne représentent pas la croissance en début de cycle, quand la plante n’a pas encore une densité de racine très développée pour aller prélever du phosphore. Cela pourrait induire une sous-estimation de la limitation en phosphore dans notre étude.
De fait, lorsqu’une plante a un système racinaire peu développé, elle peut avoir des difficultés à s’approvisionner en phosphore, malgré une quantité totale de phosphore disponible dans le sol importante. Cela s’explique par le fait que le phosphore est un élément peu mobile dans le sol que la plante peut l’absorber seulement à 1 millimètre autour de sa racine. Dans ce contexte, du phosphore issu des engrais minéraux est parfois appliqué en « effet starter » pour booster la croissance de la plante en début de cycle.
Sur le plus long terme, nos simulations montrent une baisse progressive logique de la disponibilité en phosphore du sol partout dans le monde. En effet, sans les engrais minéraux, les pertes par érosion des sols et le non-recyclage des excrétions humaines ne sont plus compensés par des apports extérieurs.
Que se passerait-il dans cent ans ?
Au bout de cent ans, à l’échelle mondiale, la baisse de la disponibilité en phosphore des sols engendrerait une baisse de production agricole de l’ordre de 30 % par rapport à la situation actuelle.
Cependant, nos simulations ont été effectuées sans recyclage des excrétions humaines, qui sont actuellement interdites dans le cahier des charges de l’agriculture biologique. Or, ce levier pourrait sans doute permettre de compenser l’abandon des engrais phosphatés. À l’inverse, notre scénario est optimiste dans la mesure où il simule une relocalisation des élevages à proximité des cultures pour favoriser le recyclage interne des effluents d’élevage, ce qui est loin d’être le cas aujourd’hui.
Il devient donc urgent de penser à ces alternatives et d’améliorer notre efficacité d’utilisation du phosphore, car, à l’échelle mondiale, les gisements dont viennent les engrais phosphatés vont un jour se tarir ou bien leur prix deviendra prohibitif. Ils sont également très localisés dans quelques zones du monde, avec 70 % des réserves au Maroc et au Sahara occidental, ce qui nous rend très fortement dépendants de quelques pays et du contexte dans lequel ils exploitent ces gisements.
Certaines recherches scientifiques tâchent également d’étudier la façon dont différentes cultures interagissent avec le phosphore. Nous savons que les plantes pourvues d’un système racinaire dense parviennent mieux à absorber le phosphore. Nous savons également que certaines plantes ont des racines qui excrètent des anions organiques ou des enzymes permettant d’augmenter la disponibilité du phosphore dans les sols. C’est le cas, par exemple du lupin blanc ou du sarrasin. Il reste cependant toujours difficile de quantifier la contribution de ces mécanismes d’absorption à l’échelle d’une parcelle, notamment dans le contexte français de sols plutôt bien pourvus.
Josephine Demay a reçu des financements du ministère de l’Agriculture et de la Souveraineté Alimentaire.
Bruno Ringeval a reçu des financements de l’INRAE
Sylvain Pellerin a reçu des financements de l’INRAE et de l’ANR.
La différence de régulation en fonction des canaux de diffusion des contenus audiovisuels sera-t-elle tenable à moyen terme ? Pour éclairer ce débat qui pourrait devenir critique, il est intéressant d’étudier les comportements et les perceptions des consommateurs. Ces derniers font-ils, comme le régulateur, une différence entre les contenus selon qu’ils sont diffusés dans un journal télévisé sur une chaîne nationale ou sur une plateforme audiovisuelle de partage de vidéos ?
Regarderons-nous un jour le journal télévisé de 20 heures sur TikTok ou ChatGPT ? Au premier abord, la question paraît quelque peu étrange. En réalité, elle n’est pas aussi saugrenue qu’on pourrait le croire. De récentes enquêtes réalisées sur la consommation des médias révèlent en effet qu’une frange croissante d’usagers se tourne vers les réseaux sociaux, les plateformes de vidéos et l’IA pour se divertir mais aussi s’informer.
Un « tout se vaut » risqué
Cette catégorisation brouille les frontières classiques du secteur audiovisuel (AV) autant qu’elle en bouleverse les repères historiques : des acteurs de ce secteur pourtant différents dans leur nature et leur fonctionnement, sont perçus comme équivalents par les consommateurs. Les risques inhérents à cette logique du « tout se vaut », du « tout horizontal », qui conduit les usagers à placer des environnements AV très hétérogènes sur un même plan lorsqu’il s’agit de s’informer ou de se divertir, sont d’importance.
Les conséquences de ces nouveaux comportements mettent au défi les autorités de régulation, telles l’Arcom ou l’Arcep, dans la mesure où ils renvoient à des enjeux tout à la fois :
économiques, par exemple, préserver un jeu concurrentiel entre plateformes, garantir un accès identique aux marchés pour tous les acteurs de la chaîne de valeur AV ;
politiques, avec la nécessité d’assurer un pluralisme d’opinions, de veiller au respect des principes démocratiques dans l’édition de contenus AV ;
sociaux, à l’instar de la lutte contre la haine, les discriminations en ligne et la manipulation de l’information ;
mais aussi culturels, avec la promotion de la diversité des créations audiovisuelles, la protection des auteurs et de leurs publics.
Dans sa triple mission d’informer, de protéger et d’arbitrer, le régulateur aurait tout intérêt à porter une attention appuyée aux perceptions qu’ont les consommateurs des environnements audiovisuels.
Reste à examiner précisément les mécanismes – ici catégoriels – de ces perceptions et à prendre la mesure de leurs incidences sur le futur des politiques publiques de régulation du secteur. À cette fin, un détour par la psychologie cognitive s’impose.
Qui se ressemble s’assemble
Cette discipline scientifique nous dit que nous catégorisons les objets du monde de deux principales façons. La première, appelée catégorisation « ascendante » ou « a priori », part des objets eux-mêmes. Elle s’appuie sur la similarité objective de ceux-ci. Les objets qui se ressemblent sur des attributs physiques voire sensoriels (poids, forme, taille, texture, odeur, etc.) sont regroupés dans la même catégorie.
Sur ce critère, une yourte, un chalet, un studio appartiennent à la catégorie « logement » puisqu’ils présentent des caractéristiques semblables et des propriétés typiques de cette catégorie : héberger, abriter, sécuriser des individus. Dans le champ AV, TikTok, YouTube Shorts et Instagram Reels relèvent de la même catégorie « site de partage de vidéos courtes et verticales » car leur design, leur interface, le format de leurs contenus AV, ou encore les fonctionnalités sociales et génératives qu’ils proposent à leurs utilisateurs, se ressemblent très fortement.
Quand c’est moi qui décide
La seconde manière de catégoriser, dite « descendante » ou « ad hoc », dépend des objets mais surtout de nous-mêmes et des buts que nous nous fixons. Dans cette perspective, que de nombreuses recherches scientifiques ont formalisée, les buts que nous poursuivons, et les contextes dans lesquels nous les atteignons déterminent les catégories que nous construisons.
Ces catégories ad hoc sont signifiantes car nous les formons au regard de finalités que nous nous donnons et de situations que nous vivons. Cette influence des buts et des contextes est telle qu’elle va jusqu’à défaire les catégories « a priori », évoquées plus haut. Ainsi, des œufs, un disque de poids, une ceinture de force, une balance corporelle et un débardeur de compression seront-ils mis dans la catégorie ad hoc « les choses pour faire de la musculation chez soi », alors qu’ils émanent de catégories « a priori » différentes.
Nous pensons que les mécanismes de catégorisation « descendante », et les catégories ad hoc qui en découlent expliquent pour partie les nouveaux modes de consommation AV. Il est d’ailleurs aisé de transposer les catégories ad hoc aux plateformes AV. Par exemple, YouTube, Vimeo, Instagram, Dailymotion, TikTok, Facebook et Twitch peuvent être regroupés dans la catégorie ad hoc « les plateformes AV sur lesquelles diffuser ou archiver des vidéos personnelles via son smartphone ».
Catégoriser les contenus
Dans un article publié fin 2025, nous avons essayé de confirmer cette intuition. À travers une étude expérimentale, nous avons mesuré l’effet combiné de buts et de contextes propres à la consommation audiovisuelle sur la manière dont les internautes catégorisent les environnements.
Nous avons d’abord demandé à des consommateurs d’évaluer, dans l’absolu, le caractère « similaire » (vs. « dissimilaire ») de quinze paires de plateformes audiovisuelles (AV), réparties en trois catégories : les réseaux sociaux, les plateformes AV de chaînes de télévision et les plateformes web de partage de vidéos.
Puis, chaque participant a été affecté à l’une des quatre situations créées pour l’expérience. Chacune plonge le participant dans un scénario construit autour d’un but précis à poursuivre (soit s’informer, soit se divertir) dans un contexte d’usage particulier (soit à son domicile, soit dans les transports). Une fois projetés dans le scénario qui leur avait été attribué, les participants ont dû de nouveau estimer le degré de similarité des mêmes quinze paires de plateformes AV que précédemment. Sauf que cette fois-ci, ils devaient juger cette similarité relativement à la mise en situation dépeinte dans le scénario. Les résultats obtenus sont sans ambiguïté et éclairants pour le régulateur.
De l’importance du contexte
Nos résultats indiquent qu’en dehors de toute mise en situation, la catégorisation est ascendante. Par exemple, les plateformes, comme YouTube et Dailymotion, sont estimées semblables et mises dans la catégorie a priori « réseau social », tandis que YouTube et France.tv sont considérées comme dissemblables et donc rangées dans des catégories a priori disjointes (« plateforme web de partage de vidéos » pour l’une, « plateforme AV de chaînes de télévision » pour l’autre). Autrement dit, les paires de plateformes AV similaires (vs. dissimilaires) sont bien perçues comme telles, dans l’absolu.
En revanche, lorsque les individus raisonnent à partir du scénario dans lequel ils ont été immergés, la donne est toute autre. Les plateformes AV relevant de catégories a priori dissemblables gagnent toutes en similarité sous l’effet des buts et des contextes décrits – qu’importe d’ailleurs le type de but (s’informer, se divertir) ou de contexte (en mobilité, en sédentarité) considéré.
En d’autres termes, selon les situations dans lesquelles a lieu notre consommation de contenus AV et selon les objectifs que nous poursuivons, notre manière de catégoriser des environnements AV a priori différents, change. Ils tendent à devenir identiques et à être rangés dans des catégories ad hoc qui, plutôt que de les différencier, les rapprochent.
L’impact pour la régulation
Ce résultat est crucial pour le régulateur. Il plaide pour une régulation harmonisée des plateformes AV, comme l’a d’ailleurs récemment évoqué le PDG du groupe TF1. Or l’actuel règlement européen sur les services numériques (Digital Services Act) impose des obligations accrues à certaines plateformes comme YouTube ou Facebook, tout en exemptant des services de VoD tels que Netflix. Ce traitement différencié pourrait accélérer la concentration du secteur audiovisuel autour de quelques plateformes dominantes – favorisées par ces dispositions réglementaires asymétriques – au détriment de la concurrence, du pluralisme de l’information et de la diversité culturelle dans les contenus AV proposés aux publics.
Il contredit également nos conclusions selon lesquelles si les diverses plateformes AV peuvent être perçues comme similaires par les usagers, rien ne justifie de les réguler différemment. Alors que le débat reste vif dans la littérature, notre recherche appelle clairement à la mise œuvre d’un cadre unifié de régulation de l’AV.
D’autres résultats de notre étude sont d’intérêt pour le régulateur. Ils mettent au jour les conditions précises dans lesquelles les consommateurs rapprochent ces environnements AV différents. Par exemple, notre expérience montre que les plateformes de partage de vidéos et les plateformes de chaînes de télévision sont plutôt identiques aux yeux des utilisateurs quand ils cherchent à se divertir chez eux. Idem pour s’informer en déplacement, les consommateurs ont tendance à amalgamer les plateformes web de partage de vidéos et les réseaux sociaux.
Passer de l’offre à la demande
Tous ces résultats aboutissent au même diagnostic : en matière d’AV, il est important de penser les actions d’information, de prévention et de sanction selon la perspective des consommateurs car il s’agit du public à protéger. Il faut alors épouser leurs points de vue, s’appuyer sur leurs expériences, comprendre leurs réelles motivations et saisir leurs logiques d’action. Bref, travailler autant pour eux qu’avec eux.
Des autorités comme l’Arcom en France, l’OfCom au Royaume-Uni ou la Federal Communications Commission aux États-Unis seraient donc bien avisées d’élargir leurs champs d’analyse et d’action, aujourd’hui centrés presque exclusivement sur l’offre (caractéristiques des plateformes, poids des acteurs dans la chaîne de valeur), en associant les consommateurs à la définition de leurs politiques publiques. L’ouverture de la gouvernance de ces autorités aux consommateurs, par la création d’un collège composé d’usagers, est une piste à considérer. La tenue d’une convention citoyenne sur l’audiovisuel en est une autre. Des options pour une régulation plus démocratique de l’AV existent et méritent d’être discutées. La fenêtre actuelle apparaît idoine pour le faire alors que notre Parlement se saisit de la santé et du devenir de notre audiovisuel public.
Julien Bouillé a, pour la recherche dont il est fait mention dans cet article, reçu un soutien financier de l’Université Rennes 2, du Laboratoire interdisciplinaire de Recherche en Innovations Sociétales (LiRIS) et du Conseil supérieur de l’audiovisuel (désormais Arcom) dans le cadre d’un partenariat de recherche (2017-2019).
Amélie Bellion, a reçu, pour la recherche sur laquelle se base cet article, un co-financement de l’Université Rennes 2, du Laboratoire interdisciplinaire de Recherche en Innovations Sociétales (LiRIS) et du Conseil supérieur de l’audiovisuel (Arcom) dans le cadre d’un partenariat de recherche (2017-2019).
C’est à travers la pratique du dessin que Michel-Ange s’accomplissait vraiment : un art considéré, dans la Renaissance italienne, comme le plus noble et celui dont découlaient tous les autres.
Un dessin à la sanguine de 12,7 cm sur 10,2 cm représentant le pied d’une femme, réalisé par Michel-Ange, a été vendu aux enchères et adjugé 27,2 millions de dollars (23,08 millions d’euros) le 5 février 2026, dépassant largement les 1,5 à 2 millions de dollars attendus.
Les experts pensent qu’il s’agit d’une étude pour la figure de la Sibylle de Libye, une prophétesse qui apparaît sur le plafond de la chapelle Sixtine à Rome. Michel-Ange a peint ces fresques emblématiques entre 1508 et 1512, mais il en a d’abord esquissé la composition générale et les détails dans une série de dessins préparatoires. Seuls une cinquantaine de ces dessins ont survécu jusqu’à aujourd’hui.
Si cette vente a suscité beaucoup de réactions, ce n’est pas seulement en raison de cette somme astronomique. Conservé dans des collections privées pendant des siècles, le dessin n’a été révélé au grand public qu’après que le propriétaire eut envoyé une photo à la maison de ventes Christie’s. Un expert en dessins l’a identifié comme l’une des rares études existant encore des fresques de la chapelle Sixtine.
Comme historienne de l’art spécialiste de la Renaissance italienne, je me réjouis de cette vente non pas en raison de la somme qu’elle a rapportée, mais parce qu’elle a attiré l’attention sur le dévouement de Michel-Ange au dessin, un médium qu’il privilégiait par rapport à la peinture.
« Ce n’est pas mon art »
Les historiens de l’art connaissent bien Michel-Ange grâce aux lettres et aux poèmes qu’il a rédigés ainsi qu’à deux biographies écrites de son vivant par des proches, Giorgio Vasari et Ascanio Condivi.
En 1506, le pape Jules II suspend les travaux de sculpture de Michel-Ange sur le tombeau papal de la basilique Saint-Pierre, réaffectant les fonds destinés au tombeau à la rénovation de la basilique elle-même. Michel-Ange réagit en fermant son atelier et ordonne à ses assistants d’en vendre tout le contenu, abandonnant 90 charrettes de marbre. Il quitte Rome, dégoûté.
En 1508, Jules II et son intermédiaire, le cardinal Francesco Alidosi, parviennent à ramener Michel-Ange à Rome en lui promettant une rémunération de 500 ducats et un contrat pour peindre la chapelle Sixtine. Bien qu’il ait accepté, l’artiste s’est beaucoup plaint de cette nouvelle commande. Il écrivit à son père que la peinture n’était pas son métier et déclara au pape que la peinture n’était pas son art. C’est bel et bien la sculpture, et non la peinture, qui était au cœur de l’identité de Michel-Ange.
Michel-Ange se plaignit de la peinture de la chapelle Sixtine dans un poème qu’il envoya à son ami Giovanni da Pistoia. Wikimedia
Selon la biographie de Condivi, que Michel-Ange approuva et contribua à façonner, l’artiste aurait quitté l’atelier du peintre Domenico Ghirlandaio vers 1490 pour se former dans le jardin de sculptures du puissant mécène florentin Lorenzo de Médicis. Michel-Ange plaisantera plus tard en disant qu’il était devenu sculpteur dès son plus jeune âge, grâce au lait maternel de sa nourrice, qui était la fille de tailleurs de pierre.
Au-delà de son enthousiasme pour la sculpture et de son ressentiment à l’égard de la chapelle Sixtine – qu’il qualifiait de « tragédie du tombeau » –, Michel-Ange considérait la peinture à fresque comme un travail éreintant.
« Cette torture m’a valu un goitre », écrivit-il à son ami Giovanni da Pistoia dans un poème illustré.
« Mon estomac est écrasé sous mon menton, ma barbe pointe vers le ciel, mon cerveau est broyé dans un cercueil, ma poitrine se tord comme celle d’une harpie. Mon pinceau, toujours au-dessus de moi, dégouline de peinture, si bien que mon visage fait un excellent sol pour les gouttes ! »
« Ma peinture est morte, conclut-il. Je ne suis pas à ma place – je ne suis pas peintre. »
Un grand dessein
La caricature qui accompagne le poème de Michel-Ange montre non seulement un esprit acariâtre et agité, mais aussi la façon dont il utilisait le dessin pour refléter ses émotions.
Le début du XVIᵉ siècle a vu l’essor du dessin, et celui de Michel-Ange en premier lieu. Plutôt que de se limiter à copier ou à fournir des modèles pour la peinture, le dessin a été considéré comme un exercice intellectuel, exploratoire et créatif important. Vasari, le biographe de Michel-Ange, a utilisé le terme célèbre de « disegno » pour signifier à la fois le dessin physique et la « conception » ou le concept global d’une œuvre, conférant ainsi à l’artiste un pouvoir créatif quasi divin.
Ce double sens se reflète dans le titre de l’exposition très populaire de 2017 consacrée aux dessins de Michel-Ange au Metropolitan Museum of Art de New York, « Michel-Ange : dessinateur et concepteur divin ».
Michel-Ange a réalisé de nombreux dessins pour la chapelle Sixtine, qui reflétaient les différentes significations du mot « disegno ». Il y avait ses croquis de modèles ainsi que ses rendus architecturaux et ses plans pour organiser cet immense espace. Puis il y avait les « cartons » grandeur nature dessinés pour transférer ses dessins directement sur le plafond lui-même.
Michel-Ange a également réalisé de nombreuses études de parties du corps et de gestes pour la chapelle Sixtine, notamment des yeux, des mains et des pieds. Dans un dessin pour le plafond de la chapelle Sixtine, aujourd’hui conservé au British Museum, diverses mains – peut-être inspirées des siennes – se répètent sur le côté droit de la page.
Les pieds revêtaient une importance particulière dans la conception globale de la figure humaine, et ils se situent à la croisée des intérêts de Michel-Ange pour l’art classique et l’anatomie humaine.
Le contrapposto était la posture emblématique des figures se tenant debout dans les peintures et les sculptures. Le poids du corps représenté repose sur une jambe tandis que l’autre jambe est fléchie. Le David de Michel-Ange se tient en contrapposto et même les médecins d’aujourd’hui sont impressionnés par la précision anatomique des muscles et des veines de chaque pied.
Le dessin vendu par Christie’s représentant le pied de la Sybille a probablement été réalisé d’après un modèle vivant, Michel-Ange mettant en valeur l’élégance de la prophétesse Sibylle de Libye à travers son pied dramatiquement cambré. Dans la fresque achevée, le corps de la Sibylle est une sorte de machine élégante. La musculature de ses bras tendus, son torse enroulé et son orteil pointé fonctionnent tous en harmonie. Ce petit dessin montre comment l’énergie intense exprimée par une seule partie du corps pouvait contribuer au « disegno » global de cette fresque monumentale.
Si le processus de peinture du plafond fut ardu, celui de sa conception à travers le dessin fut manifestement gratifiant pour Michel-Ange.
La fresque achevée de la Sibylle de Libye dans la chapelle Sixtine. Wikimedia
Le dessin comme pivot
Malgré la popularité des fresques de la chapelle Sixtine, Michel-Ange ne revint que rarement à la peinture après les avoir achevées. En 1534, le pape Clément VII lui commanda de peindre le Jugement dernier sur le mur de l’autel de la chapelle Sixtine. Mais ce n’est qu’après la mort de Clément plus tard dans l’année – et après que son successeur le pape Paul III eut nommé Michel-Ange architecte en chef, sculpteur et peintre du palais du Vatican – que l’artiste a commencé à travailler sur le mur de l’autel.
Si beaucoup de gens aujourd’hui pensent aux fresques de la chapelle Sixtine ou à la Joconde de Léonard de Vinci lorsqu’ils évoquent la Renaissance italienne, ces artistes ne se considéraient pourtant pas avant tout comme des peintres.
Dans une célèbre lettre de présentation adressée au duc de Milan, Ludovico Sforza, Léonard de Vinci détaille ses nombreuses compétences en matière de fortifications, d’infrastructures et d’armement. Il se vante de son aptitude à construire des ponts, des canaux, des tunnels et des catapultes. Ce n’est qu’après dix paragraphes qu’il ajoute une seule phrase admettant qu’il est également capable « de réaliser des sculptures en marbre, en bronze ou en argile, et qu’en peinture, il peut accomplir n’importe quel type de travail aussi bien que n’importe quel homme ».
Tout comme ceux de Michel-Ange, les dessins de Léonard témoignent d’un esprit vorace. Ils explorent, plutôt que de simplement observer, tout ce qui va des machines militaires à l’anatomie humaine. En 1563, Michel-Ange fut nommé maître de l’Accademia del Disegno de Florence, qui avait pour objectif d’enseigner le dessin et la conception en tant que compétences fondamentales nécessaires à la sculpture, à l’architecture et à la peinture.
Le dessin, en fin de compte, était l’art qui unifiait les nombreuses activités de l’« homme de la Renaissance ».
Anna Swartwood House ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
Source: The Conversation – France – By Farid Lamara, Responsable de programmes de recherches, Agence Française de Développement (AFD)
United Nations member states unanimously adopted the sustainable development agenda in 2015. It aims to ensure development that “meets the needs of the present without compromising the ability of future generations to meet them” (1987 Brundtland Report, “Our Common Future”). This agenda outlines 17 Sustainable Development Goals (SDGs) and sets out 169 targets to be achieved by 2030. They represent the programme’s accountability framework.
None of the 17 Sustainable Development Goals (SDGs) is specifically devoted to human rights. In reality, they are everywhere – at the heart of the social, economic, cultural, civil, and political life of all inhabitants of the world, but also at the centre of contemporary ecological issues, which the United Nations General Assembly endorsed in 2022 through a historic resolution acknowledging the right to a healthy environment as a human right.
‘Strong sustainability’, a prerequisite for preserving nature and the universality of human rights
On the whole, the SDGs combine environmental, economic, human development and governance issues. However, there are several competing visions, based on different economic and environmental assumptions, regarding how to achieve them. These are referred to as “weak” and “strong” sustainability. The latter is a concept that aims to strengthen sustainable development by ensuring that economic policies do not compromise (or sacrifice) human development, the environment or nature.
Unlike weak sustainability (based on the concepts of the substitutability of natural capital), strong sustainability is based on the principle that natural capital is irreplaceable and must be preserved.
Three key principles of strong sustainability stand out:
the finite nature of the environment
social justice
the limits to economic growth.
Within this framework, the human rights-based approach and the approach based on the rights of nature are essential for truly sustainable development. This involves recognising nature – ecosystems and natural entities – as a subject of law.
Today, more than 650 initiatives recognising the rights of nature have been documented. Without these approaches, the current system exacerbates inequalities and threatens the habitability of the planet.
What emerges from this overview is that the (anthropogenic) ecological crisis exacerbates inequalities and severely undermines human rights – both substantive (the right to life, health, food, housing, etc.) and procedural rights (the right to participation, information and redress), primarily among vulnerable populations: children, women, indigenous peoples and local communities, human rights and environmental defenders, migrants and displaced persons.
Environmental governance meanwhile remains inadequate, with governments and the private sector generally limiting themselves to a risk-reduction approach (“no harm done”) that lacks accountability and an integrated, proactive vision of human rights, the right to a healthy environment, and the rights of nature. It thus, appears urgent to come up with other alternative models incorporating accountability, justice (social and environmental) and citizen participation for reconciling ecology and human rights within an eco-centred rather than anthropocentric approach.
Especially now that the planet’s limits have been largely exceeded.
Looking at the planet’s limits from a human rights perspective
These limits (see chart below) define the safe operating space for humanity in relation to the terrestrial ecosystem and are linked to the planet’s biophysical subsystems or processes. Today, 7 out of 9 boundaries have been exceeded. And since the adoption of the SDGs in 2015, 3 have been exceeded.
Beyond the significant impact on the natural world, the implications for human rights are systemic. Take the right to health, for example evidence shows that each “planetary limit” has direct consequences for human and animal health and ecosystems.
As far as human health goes, chemical pollution (pesticides, plastics, persistent organic pollutants) causes a range of chronic illnesses and an increase in cancer cases.
Air pollution alone causes more than 4 million deaths worldwide every year.
Premature deaths linked to heatwaves (climate), malnutrition (changes in the water cycle), soil degradation or the decline in biodiversity further exacerbate the health toll and human mortality, primarily affecting the poorest populations, particularly in a world governed by a profoundly asymmetrical and unequal model.
Inequality as a driving force behind the ecological crisis and the erosion of human rights
According to the World Inequality Lab’s 2025 report on climate inequality, the poorest 50% of the world’s population account for 10% of greenhouse gas (GHG) emissions, which is significantly less than the emissions of the richest 1%. The latter, moreover, are solely responsible for 41% of GHG emissions linked to the ownership of assets (both financial and non-financial).
The poorest 50% are not only the least responsible. They are also the most vulnerable to loss and damage, whilst having the least financial capacity to cope with it. And if we look at income and wealth inequality, we see that the richest 10% of the world’s population harness more income than the remaining 90%. Overall although inequality has been rising sharply within countries for several decades, these findings point to very significant North-South disparities. Yet the greater inequality, the less ability people have to assert their rights.
The inconsistencies of an asymmetrical and unequal model in the 2030 Agenda
Under these circumstances, achieving the expected outcomes of the 2030 Agenda is a long shot. The 2025 United Nations report on the SDGs shows that of the 169 SDG targets, only 18% have been met or are on track to be met by 2030. And 66% of them show marginal progress, stagnation or regression.
A more detailed analysis, SDG by SDG, shows that several of them will not meet any of their targets by 2030. This is particularly the case for SDG 1 (poverty), 5 (gender), 6 (water), and 16 (peace, justice and strong institutions). Meanwhile, SDGs 2 (hunger), 3 (good health), 4 (quality education), 10 (reduced inequalities) and 13 (climate action) are expected to meet only one target each.
Given that human rights form the backbone of the SDGs, these results demonstrate that issues of justice remain marginal in their operational implementation.
On the other hand, democratic backsliding, the decline in human rights and the extreme narrowing of civic space that is materialising, for example, in censorship and the violent repression of journalists, human rights and environmental defenders, peaceful protesters, etc. – around the world are further obstacles to their achievement.
Today, according to the Civicus Monitor, only 7.2% of the world’s population lives in an “open” or “reduced” civic space. The rest live in a “restricted” (19.9%), repressed (42.3%) or closed (30.7%) civic space.
It is therefore becoming urgent for the international community in general, and development actors in particular, to give full priority to approaches based on human rights and the rights of living things in the implementation of the 2030 Agenda.
Human rights and the rights of nature: a vital symbiosis for future generations
To achieve this, the challenges associated with the dominant economic model and global governance must be considered. This goes far beyond the legal sphere.
And yet the rights of nature are powerful levers for strengthening human rights and vice versa, as recently recognised by the International Union for Conservation of Nature (IUCN) through the adoption of several resolutions.
With this in mind, the approach based on human and living rights should be integrated into all public policies aimed at achieving SDGs, with a strong focus on sustainability.
This is precisely what the COP15 Kunming-Montreal Decision on Biodiversity states, calling for action to support Mother Earth, that is to say, an “eco-centric and rights-based approach conducive to the implementation of actions aimed at establishing harmonious and complementary relationships between people and nature, promoting the sustainability of all living beings and their communities, and avoiding the commodification of the environmental functions of Mother Earth”.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Farid Lamara ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
Les enquêtes sur les cold cases, ces meurtres non résolus depuis des décennies, reposent sur des méthodes souvent méconnues. L’analyse victimologique et la connaissance du cercle proche des victimes permettent de faire émerger de nouveaux indices. Récit d’une enquête portant sur le meurtre d’une adolescente, survenu il y a quarante ans.
Lorsque les policiers arrivent sur son lieu de travail, Anne ne peut imaginer que c’est pour elle qu’ils font le déplacement. De l’annonce, elle ne retient que quelques mots, secs et hachurés : sa fille unique de 16 ans a été tuée de plusieurs coups de couteau au sein du domicile familial. Malgré le choc, les proches sont rapidement entendus : la famille, puis les amis, les camarades et les voisins.
Nous sommes dans les années 1980, l’enquête sur le meurtre de Sophie ne fait que débuter (le prénom de la victime et certains éléments ont volontairement été modifiés).
À l’époque, l’ADN n’est pas encore au cœur des investigations criminelles et aucune trace génétique ne sera collectée. Alors, quand l’Office central pour la répression des violences aux personnes (OCRVP) reprend l’affaire quarante ans plus tard, il faut mobiliser d’autres leviers pour retrouver le meurtrier.
L’unité d’analyse comportementale (UACP), formée de trois psychocriminologues, constitue l’un des outils mis à la disposition des enquêteurs pour reprendre ces affaires complexes restées irrésolues.
L’entourage : premier suspect
L’annonce d’un décès dans des circonstances criminelles constitue, pour les proches, une épreuve émotionnelle. Elle les confronte à une réalité brutale susceptible d’altérer temporairement leurs capacités de compréhension, de réaction et d’expression. Si certaines manifestations sont attendues (pleurs, cris, colère), d’autres réponses, telles que la sidération, la distanciation ou une apparente froideur, peuvent également survenir. Ces réactions ne sauraient être interprétées comme une absence d’affect : elles relèvent fréquemment d’un état de choc. Il importe, dès lors, de ne pas assimiler ces mécanismes défensifs à des indices de dissimulation.
Cependant, cette lecture clinique ne peut occulter les réalités de l’enquête criminelle qui conduit souvent à orienter les investigations vers l’entourage de la victime. Les statistiques criminologiques montrent en effet que, dans de nombreux homicides, l’auteur appartient au cercle familial ou relationnel.
D’après les données du ministère de l’intérieur, en 2023, sur les 996 personnes décédées à la suite d’un homicide en France, environ une sur quatre l’a été dans un cadre familial. Et lorsque l’on considère spécifiquement les victimes féminines, plus d’une sur deux a été tuée dans un contexte intrafamilial.
À l’échelle internationale, les recherches criminologiques menées à partir d’homicides résolus montrent que les meurtres commis par des auteurs totalement inconnus de leurs victimes restent rares. Ils représentent en moyenne entre 9 % et 20 % des cas, selon les pays et les périodes étudiées. Une recherche menée en 2021 en Algérie confirme encore ces résultats : dans plus de 80 % des homicides étudiés, un lien de connaissance existe entre la victime et son meurtrier (dans 21 % des cas il s’agit d’un membre de la famille, dans 12 % d’une relation intime, dans 28 % d’un voisin, dans 14 % d’un ami, dans 6 % d’une relation professionnelle).
S’agissant du meurtre de Sophie, un facteur de vulnérabilité spécifique doit aussi être intégré à l’analyse : l’adolescence. Des travaux menés en 2024 en Italie indiquent que, entre 13 et 18 ans, les jeunes femmes sont tuées par un partenaire intime dans neuf cas sur dix (62 % par le partenaire actuel, 26 % par un ancien partenaire).
Lorsque l’auteur est identifié, le profil correspond à celui d’un jeune homme légèrement plus âgé que la victime (environ + 3,9 ans). Dans plus de la moitié des situations, le passage à l’acte s’inscrit dans un contexte de rupture ou de conflit amoureux.
Au vu de ces éléments, les enquêteurs procèdent dès que possible à l’audition de l’entourage de la victime, afin de mieux cerner quelles étaient ses préoccupations, ses dynamiques relationnelles et ses histoires adolescentes. Si l’on en croit ces données chiffrées, le criminel serait juste là, caché dans son cercle de connaissance.
Les biais cognitifs dans les enquêtes
Les parents endeuillés sont-ils vraiment des témoins fiables ? Tandis que l’enquête vise à objectiver le profil d’une victime, les parents évoquent avant tout leur enfant, investi d’une forte charge affective. Cette proximité favorise l’émergence de biais cognitifs lors des déclarations initiales : idéalisation post-mortem, minimisation des conflits, biais de loyauté familiale ainsi que des mécanismes défensifs liés à la honte ou à la culpabilité. En relisant les premières auditions, cela transparaît souvent dans certaines formules récurrentes des proches, telles que « Elle n’aurait jamais fréquenté de mauvaises personnes », « Elle était appréciée de tous » ou encore « J’aurais dû être au domicile ce jour-là ».
S’y ajoutent des phénomènes de contamination intertémoins, les échanges intrafamiliaux contribuant à l’élaboration d’un récit homogénéisé. Il en résulte fréquemment la construction d’un portrait lissé : famille sans difficulté, adolescente sans problème, dans lequel certains aspects de la vie intime restent dans l’ombre.
Afin de limiter les effets des biais cognitifs dans la conduite des enquêtes, les services de police recourent à des grilles structurées d’exploration victimologique. Ces outils méthodologiques visent à examiner de manière systématique l’ensemble des dimensions de la vie de la victime : sphère affective et sexuelle, relations sociales et professionnelles, vulnérabilités, habitudes de vie ainsi que d’éventuels changements récents de comportement.
La structuration des informations recueillies permet ensuite une mise en perspective comparative des données, faisant apparaître les convergences, les divergences, les zones d’ombre ou encore les éléments susceptibles d’avoir été tus. Dans le cadre de la réouverture d’un dossier ancien, ces portraits victimologiques constituent un appui essentiel aux nouvelles auditions : ils orientent les investigations vers les éléments demeurés lacunaires, insuffisamment explorés ou précédemment passés sous silence, et favorisent ainsi une reprise d’enquête plus exhaustive et méthodologiquement sécurisée.
Dans l’affaire criminelle du meurtre de Sophie, l’analyse conduite au sein de l’OCRVP a mis en évidence une période de remaniement identitaire marquée, où la contestation des normes parentales et les conduites transgressives s’inscrivaient dans un processus adolescent classique.
Les auditions des amies se révèlent, à cet égard, particulièrement fécondes. Elles font émerger des éléments souvent ignorés du cercle familial : des expériences affectives et sexuelles, l’usage de cannabis et d’alcool en soirée et, un projet de fugue pour rejoindre celui qu’elle pensait être son grand amour.
Toutefois, l’examen psychocriminologique suggère également l’existence d’un décalage possible entre les récits livrés au groupe de pairs et la réalité des conduites de Sophie : certaines expériences semblent avoir été enjolivées pour se donner une image plus téméraire, plus audacieuse. Dès lors, l’enjeu analytique ne réside pas seulement dans l’accumulation d’informations factuelles, mais aussi dans l’appréhension des écarts entre les différentes représentations sociales de la victime afin de cerner, au plus près, la dynamique identitaire à l’œuvre.
L’analyse victimologique
L’analyse victimologique, dans le cadre de l’enquête criminelle, est l’étude de la victime permettant de déduire les circonstances de sa sélection par l’auteur et la dynamique du crime. À l’OCRVP, cette analyse est réalisée par les psychologues de l’Unité d’analyse comportementale psychocriminologique.
Cependant, cette discipline a longtemps occupé une place secondaire au profit du profilage criminel, focalisé quasi exclusivement sur le criminel recherché. Le profilage s’est, en effet, historiquement construit à partir de l’analyse des traces comportementales laissées sur la scène de crime (mode opératoire, signature, mise en scène), à partir desquelles les enquêteurs tentaient d’inférer les caractéristiques du suspect.
Pourtant, les travaux de criminologues spécialisés dans l’analyse comportementale, comme Wayne Petherick ou Brent Turvey, soulignent le rôle central de la connaissance de la victime dans la compréhension du processus criminel. C’est en croisant l’analyse victimologique et le profilage criminel du suspect que l’on peut éclairer trois aspects essentiels de l’enquête : le contexte du crime, les liens éventuels entre auteur et victime, et les pistes d’investigation à privilégier.
Le lieu dans lequel se trouvait la victime, sa vulnérabilité et sa capacité à se défendre donnent des indices sur la façon dont le meurtrier a agi. Celui-ci choisit souvent sa victime en fonction de ce qu’elle lui permet de réaliser : satisfaire des fantasmes, répondre à ses pulsions ou simplement profiter d’une opportunité donnée. L’analyse victimologique, articulée aux éléments objectivés sur la scène de crime, permet ainsi d’inférer le mode d’approche, le mode d’attaque, les risques assumés et, dans une certaine mesure, le mobile.
L’analyse victimologique du meurtre de Sophie éclaire plusieurs traits du comportement de l’auteur. L’adolescente n’ouvrait pas la porte aux inconnus, suggérant une approche par ruse mobilisant certaines compétences sociales. Le crime survient alors qu’elle est seule à son domicile, dans le cadre d’une activité routinière, laissant penser à un repérage préalable et à une capacité d’anticipation.
Son caractère « calme », sa petite corpulence et ses faibles capacités de résistance physique indiquent de la part de l’agresseur une violence disproportionnée et une perte de contrôle émotionnel, suggérant un auteur colérique et impulsif. L’autopsie révèle également que Sophie n’a pas été violée, ce qui nous oriente vers un mobile non sexuel. Enfin, le corps n’a pas été déplacé et la scène n’a fait l’objet d’aucune mise en scène, ce qui laisse penser à un départ précipité.
Affaire à suivre
La reprise du dossier par les enquêteurs de l’OCRVP ouvrira la voie à l’exploration de nouvelles hypothèses, notamment par la réaudition des témoins de l’époque. Leur mémoire sera-t-elle altérée par les années ? Ou le temps deviendra-t-il un allié ?
Certains dossiers traités au sein de l’OCRVP enseignent que les années passées peuvent transformer les dynamiques psychologiques et relationnelles des témoins. L’éloignement émotionnel, la maturation individuelle ou la reconfiguration des liens interpersonnels sont susceptibles de lever d’anciennes inhibitions et de délier certains secrets.
Ces remaniements psychiques favorisent parfois l’émergence d’éléments demeurés tus au moment des faits : un terrain d’analyse privilégié pour les psychocriminologues.
Créé en 2023, le Centre de recherche de la police nationale pilote la recherche appliquée au sein de la police nationale. Il coordonne l’activité des opérateurs scientifiques pour développer des connaissances, des outils et des méthodes au service de l’action opérationnelle et stratégique.
Magalie Sabot ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
Canada positions itself as a nation in need of skilled immigrants to address labour shortages, support an aging population and drive economic growth. But the reality of Canada’s labour market tells a different story.
Upon arrival, the credentials of the talent attracted from abroad often face skepticism. The issue isn’t just about integration, it’s about the bigger problem of how Canada recognizes and values educational backgrounds, skills and professional experience.
At the centre of that failure is the idea of “Canadian experience.” This refers to the requirement that job applicants have prior work experience in the Canadian labour market to gain further employment.
Employers often defend this requirement as practical. They argue it ensures that workers understand local norms, workplace culture and regulatory expectations. In practice, this requirement acts as a screening tool.
This is both a social and an economic mistake. Canada’s immigration policy is based on the idea that newcomers are crucial to its future success. Yet it continues to squander the skills of the professionals it accepted to take in.
As a researcher specializing in immigration and international student retention in Canada, I believe the system isn’t failing at selecting talent, it’s failing at recognizing it.
Immigrants aren’t the problem, recognition is
A report from RBC found that immigrants often struggle to secure suitable employment in Canada because their training or field of study does not align with labour market needs. This explanation is incomplete, as data shows that a majority of immigrants with a post-secondary education are often more over-qualified than Canadian-born workers.
In September 2025, 34.7 per cent of recent immigrants reported being over-qualified compared with 18.5 per cent of Canadian-born workers. This suggests that many immigrants are failing because their skills are not being fully acknowledged or used.
Immigrants didn’t arrive without skills. They were carefully selected for the strong education, experience and qualifications that met Canada’s immigration standards. The problem starts after they arrive, when their qualifications face even deeper scrutiny.
Most employers ask for Canadian experience as a prerequisite, creating an impossible cycle: newcomers cannot gain Canadian experience without being hired, yet cannot get hired without Canadian experience.
At the core of the problem is a tendency to view unfamiliar foreign experience as a liability rather than as evidence of skill. Employers usually trust what they know. Regulatory bodies focus on credentials they easily understand. So foreign training is often seen as uncertain until it’s translated into Canadian terms.
The problem repeats across immigration streams
Two groups highlight this issue clearly: international students and internationally trained doctors. Although they differ in many ways, both show how Canada delays or denies recognition of people it has invited.
International students often come to Canada for the promise of education and work that can lead to a better future. However, they soon face a tough reality: costly housing, tight finances and immigration rules that limit their options.
To make ends meet, many take jobs in retail, food service, warehouses, delivery or care work. These roles are essential and demanding, yet they don’t provide the professional experience or career advancement that students expect.
International students are encouraged to work, contribute and build a life in Canada. Yet the jobs available to them, while technically providing Canadian work experience, are not in their fields of study. After graduation, employers often dismiss this experience as irrelevant and continue to demand professional Canadian experience in their specific industry, which students had no opportunity to gain.
In 2021, Canada had roughly 39,000 internationally educated people with medical training, yet only 41.1 per cent of foreign-educated doctors were working in related occupations, compared with about nine in ten Canadian-educated medical graduates.
Many of these doctors come with strong clinical knowledge and experience from other health systems. Yet in Canada, their qualifications must go through extensive verification processes, credential checks and limited licensing pathways.
While these requirements are set up to ensure the Canadian health-care system can meet the highest standards of care, they also create barriers for foreign-qualified professionals.
What Canada keeps getting wrong
Canada seeks global talent but builds systems that undervalue it. This contradiction could explain why labour shortages in healthcare and certain skilled trades persist despite high-skilled immigration streams.
To gain real benefits from immigration, Canada must improve how it recognizes and integrates foreign expertise. And it should stop using “Canadian experience” as a method of exclusion.
Underusing skilled immigrants is both unfair to them and harms the economy. Canada can’t claim it needs talent from abroad while discounting it once it arrives.
George Kofi Danso does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.


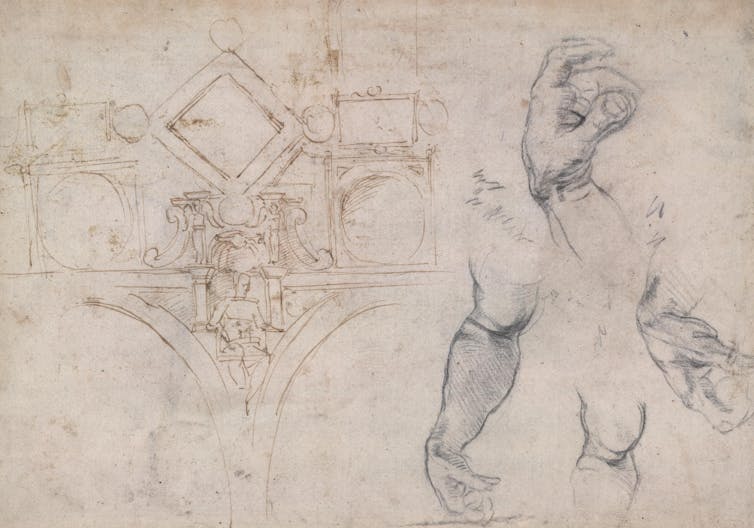
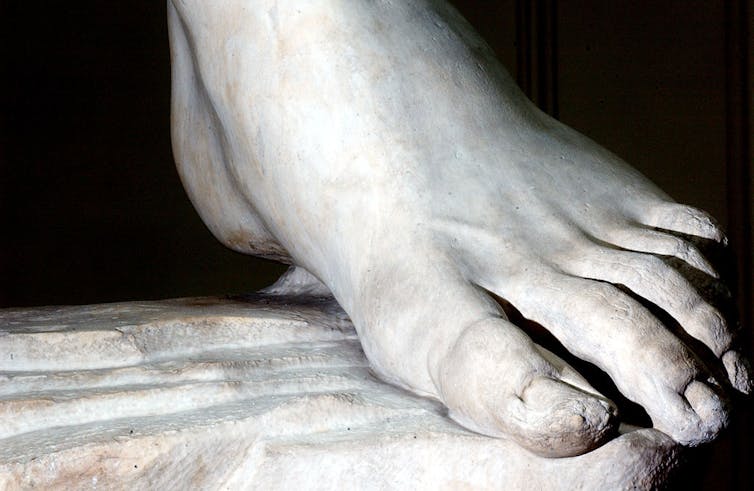


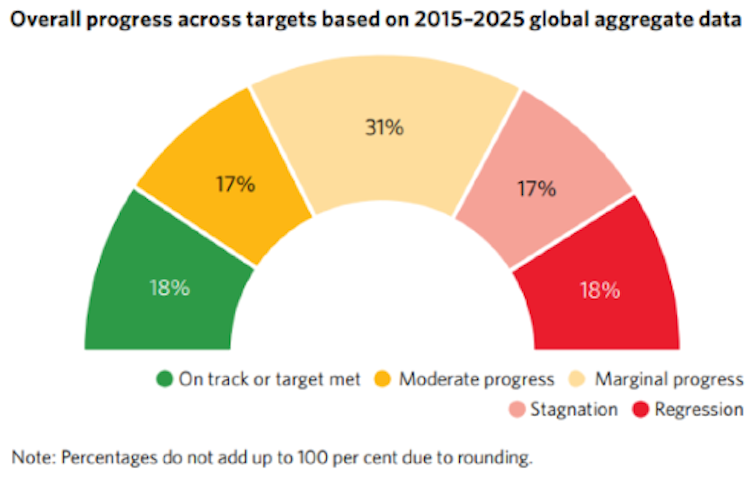
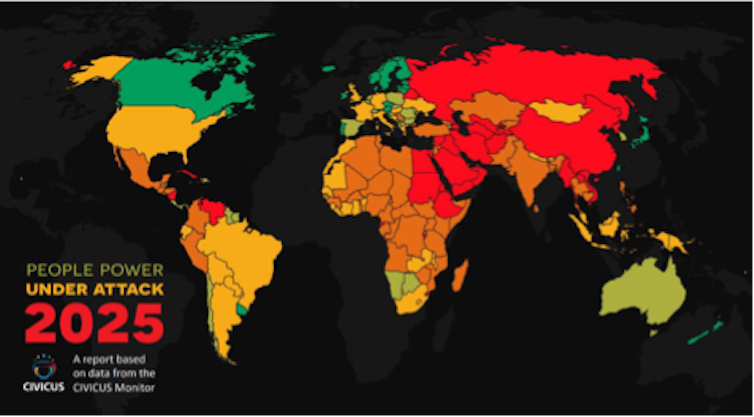

{kind=link}
{kind=link}